Defining the spoiler effect
Whether or not you’ve heard the term “spoiler effect,” you have probably lived through one. In the 1992 presidential election, independent candidate Ross Perot notably won 19% of the popular vote, arguably propelling Democrat Bill Clinton towards a win against Republican incumbent George H.W. Bush.
Maybe you were disillusioned with the major party nominees in the 2016 presidential election, and looked to Jill Stein or Gary Johnson as an alternative. If so, you may have been told that voting for Stein would actually help Trump win, or that voting for Johnson would help Clinton win.
However, it would be misguided to blame third party and independent candidates for this dynamic. If our presidential elections are so fragile that a third party candidate can throw the entire system into disarray, the problem isn’t with the candidate, it’s with our elections. Ballots should offer multiple meaningful choices, but plurality voting instead creates a derivative choice between two candidates.
This is one of the main appeals of ranked choice voting (RCV). With RCV, you can vote for your favorite candidate, and if that candidate becomes unviable, your vote can count towards your next choice. Voters split between candidates with similar views in the first round can work together in later rounds. Diverse startup candidates can run and share their ideas without “spoiling” the race for another candidate.
Recently, a handful of commentators have peddled misleading “examples” of the spoiler effect. One claims that Kurt Wright “spoiled” the 2009 Burlington mayoral RCV race, because if he had not run, Andy Montroll would have won. Another claims that Sarah Palin “spoiled” the 2022 special US House election in Alaska, because if she had not run, Nick Begich would have won. They both claim that if a number of voters had switched their preferences, the outcomes would have been different.
These are not examples of the “spoiler effect.” These are claims that are true in any electoral system:
- Who wins an election depends on who runs in that election.
- If some voters voted differently, someone else could win.
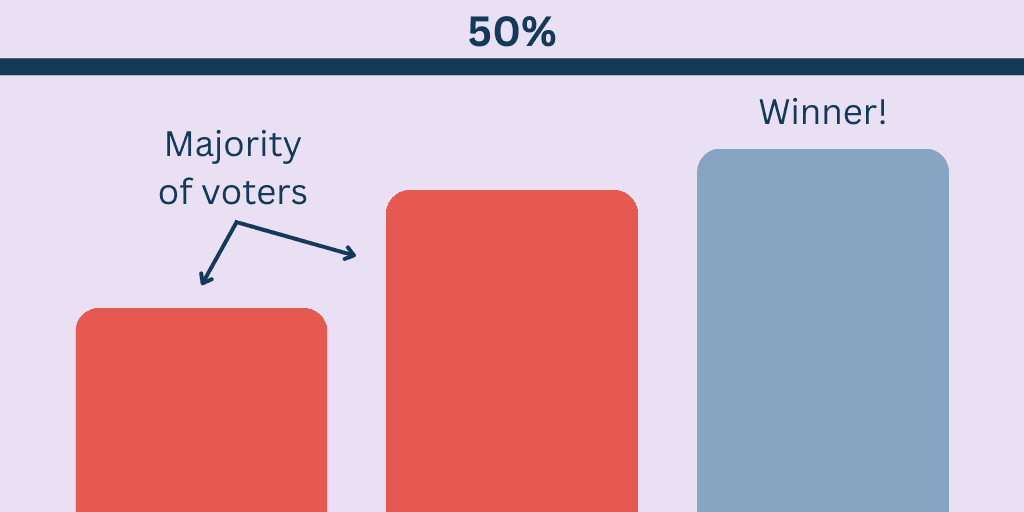
The spoiler effect refers to when votes in a majority bloc are splintered between several candidates, helping the minority bloc win. It does not refer to the fact that who runs will ultimately have an impact on the outcome. We could speculate in any election that “if A candidate had run,” or “if B candidate had not run,” or “if more voters preferred C to D,” the result might have changed. However, in both the Burlington and Alaska instances, RCV elected the candidate with the strongest first-choice and backup support, given the options on the ballot.
For example, Palin did not “spoil” the race for Begich, because she did not split the Republican vote. Voters were not simply split into partisan blocs as suggested, demonstrated by the fact that many of Begich’s supporters ranked Democrat Mary Peltola second, and that Peltola built on her lead just two months later. Alaska allows voters to rank every candidate on their ballot, so if more Begich voters had wanted to rank Palin second, they could have; rather than cause vote-splitting, RCV allowed more Begich voters to have their ballots count in the final round.
The defining dynamic of the “spoiler effect” is when vote-splitting causes a minority-preferred outcome, and RCV helps prevent this dynamic. RCV ensures:
- You can cast your ballot freely without fear of “wasting” or “splitting” votes.
- A consensus (50% of active ballots) will be reached and rewarded, whether in the first or later rounds.
- A voter-supported outcome based on who actually ran and who voters actually preferred.
Note:
The criterion these commentators reference is actually called the “independence of irrelevant alternatives” (IIA), coined by Kenneth Arrow in 1951. It is not the same as the spoiler effect. It is one of the criteria evaluated in Arrow’s Impossibility Theorem, which finds that no ranked ballot system can achieve all of the criteria Arrow lists (and other works have demonstrated that non-ranked methods have similar flaws, too). In other words, no system is perfect. Moreover, one could argue that competition should be consequential, that non-frontrunners should somewhat influence the outcome of the race.
Though we should certainly care about academic evaluation of electoral systems, we should not let one highly theoretical, devoid-of-reality criterion call into question systems like RCV that are proven effective at producing consensus winners.



